
Large amounts of scientific information are still hidden in primary scientific publications and not available as curated data in open scientific databases. Making this information publicly available to support open science and open innovation is a timely challenge. We address this problem with deep learning approaches. Our showcase is natural products research where we aim to resurrect the wealth of information that scientists already reported about the metabolites and their structures in primary scientific literature. Apart from their structure, we are interested in the species and organism parts in which natural products have been found. Besides text-based approaches for information mining, develop methods for Optical Chemical Structure Recognition (OCSR), the process of converting a bitmap image of a chemical structure into a computer-readable format. Over the last three decades, a variety of tools has been developed to address this task. Most tools that have been published until 2019 are rule-based systems. Out of all these tools, only three were open-source and freely available to everyone. The rise of deep learning approaches has contributed to a renewed interest in this field.
We work on addressing the aforementioned visual computing problem as well as other tasks which are related to chemical literature mining using deep learning methods.
The Deep Learning for Chemical Image Recognition (DECIMER) project.

DECIMER is a novel deep-learning-based algorithm built to solve the visual computing challenge of detecting chemical structure depictions in the full-text versions of the primary chemical literature and translating them into machine-readable chemical graphs. The central part of the project has two components:
- DECIMER-Segmentation: an open-source, deep-learning-based tool for automatically recognising and segmenting chemical structure depictions from the scientific literature.
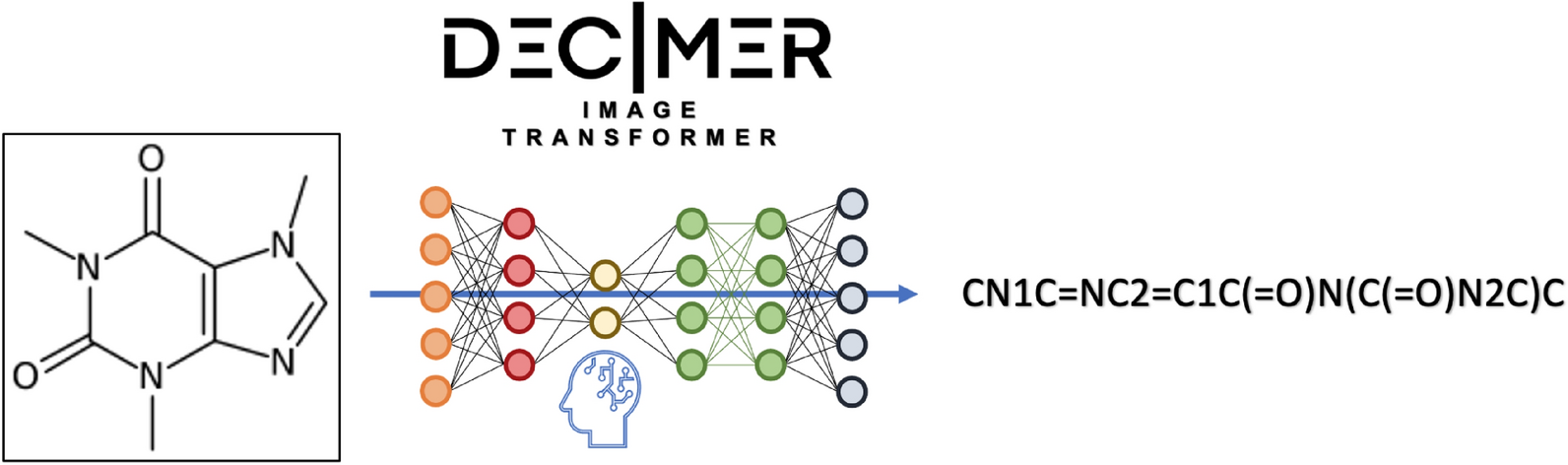
- DECIMER-Image Transformer: a deep learning-based system that uses a convolutional neural network to extract the image features and a transformer network to decode the image features into a computer-readable representation, such as SMILES.
DECIMER-Segmentation
The DECIMER-Segmentation tool combines a Mask-RCNN model and an in-house developed mask expansion algorithm. Training on only 9992 annotated regions from less than 1000 publications has allowed the tool to recognise and segment chemical structure depictions from the printed literature with more than 90 % accuracy. We hope that by making the source code and the trained model public, we can contribute to the development of comprehensive chemical data extraction workflows. A web application has also been designed to facilitate access to DECIMER Segmentation. Users can upload a pdf file and download segmented structures using the web application, available at decimer.ai.

DECIMER – Image Transformer
Our DECIMER – Image to Smiles project pioneered the use of an encoder-decoder deep neural network model for chemical image depiction to SMILES translation. To scale up the network and to train the network with millions of data points carefully selected with filtering rules. The DECIMER Image to SMILES model has been modified to make use of a more efficient and accurate transformer-based network. As a result, we introduced the DECIMER-Image Transformer model. The DECIMER-Image Transformer demonstrated an accuracy of approximately 89 % for the chemical structure images with stereochemical information and ions. For the images without stereochemical information and ions, it was 96 %. DECIMER is fully open-source and hosted on GitHub. All data and trained models are publicly available.
STOUT – SMILES to IUPAC name translation
A chemical compound can be identified through a graphical depiction, a string representation, or its chemical name. An internationally recognized naming scheme for chemistry has been established by the International Union of Pure and Applied Chemistry (IUPAC). Due to the complexity of the ruleset, chemical name assignment remains difficult for humans; only a few rule-based cheminformatics tools support this process automatically. These tools are usually commercial and require an exclusive license. As a result, researchers cannot access such tools due to this licensing requirement. Due to the complexity of building a tool that is able to apply all the rules defined by the International Union of Pure and Applied Chemistry (IUPAC) for naming compounds, there were no open-source solutions.

Hence, to generate IUPAC names from a given chemical structure without any predefined rules the SMILES to IUPAC (STOUT) project was initiated to resolve this issue by building an open-source tool based on neural machine translation (NMT). STOUT can be used to generate IUPAC names for a chemical structure given in a SMILES representation. Furthermore, STOUT can also translate the IUPAC names back to SMILES.
DECIMER and STOUT are made openly available to the general public to facilitate research in related fields.
Publications
- Rajan, K., Zielesny, A. & Steinbeck, C. DECIMER: towards deep learning for chemical image recognition. J Cheminform 12, 65 (2020). https://doi.org/10.1186/s13321-020-00469-w
- Rajan, K., Brinkhaus, H.O., Sorokina, M. et al. DECIMER-Segmentation: Automated extraction of chemical structure depictions from scientific literature. J Cheminform 13, 20 (2021). https://doi.org/10.1186/s13321-021-00496-1
- Rajan, K., Zielesny, A. & Steinbeck, C. DECIMER 1.0: deep learning for chemical image recognition using transformers. J Cheminform 13, 61 (2021). https://doi.org/10.1186/s13321-021-00538-8
- Rajan, K., Zielesny, A. & Steinbeck, C. STOUT: SMILES to IUPAC names using neural machine translation. J Cheminform 13, 34 (2021). https://doi.org/10.1186/s13321-021-00512-4